
AI-assistenten zoals ChatGPT, Gemini en LeChat blijven in hun razendsnelle evolutie tot de verbeelding spreken. Ze zorgen ervoor dat alle pioniers die de vlag van innovatie zwaaien, mee op de kar willen springen. Fantastisch vanuit het perspectief van AI-adoptie in Vlaanderen, maar vanuit overwegingen in AI-geletterdheid een uitdaging voor duurzame innovatie.
Begrijp me alvast niet verkeerd. Artificiële intelligentie (AI) brengt ons tal van opportuniteiten als het aankomt op kwaliteitsvol onderzoek en onderwijs. De ontwikkelingen binnen AI kunnen we in vele domeinen onmogelijk negeren, of we dreigen achterop te hinken. AI zorgt ongetwijfeld voor efficiëntiewinsten en biedt gigantische opportuniteiten om de focus te verleggen van steeds terugkerende, repetitieve taken naar kwaliteit. Kwaliteit met focus op de mens, waaruit dan weer nieuwe opportuniteiten kunnen ontstaan om verder te innoveren.
Experimenteren met de huidig beschikbare modellen brengt ons die nieuwe perspectieven. We zien elke dag wel een nieuwe case voorbijkomen waarin een AI-assistent een proces kan ondersteunen. Cases die bijna in elk domein terugkomen. Denk aan een assistent die studenten kan uitdagen in hun kennisontwikkeling, of die je bijstaat om snel informatie terug te vinden. In de zorgsector zouden dankzij een AI-assistent nog sneller inzichten opgedaan kunnen worden over patiënten, terwijl de muzieksector nieuwe inspiratie vindt in de ‘creativiteit’ van AI-modellen. Om maar te stellen: AI is er, en AI zal zich blijven verspreiden tot het net als de computer of smartphone een belangrijk centraal element wordt in vele verschillende contexten.
Het probleem? Wel, het lijkt misschien net iets te simpel allemaal. Door de ongelooflijke impact op onze huidige manier van werken leiden de opportuniteiten ons soms af van belangrijke overwegingen die raken aan de slaagkansen en duurzaamheidsaspecten van de cases. Want ja, ChatGPT gebruiken, wat is daar nu zo moeilijk aan? Zo’n AI-assistent lijkt ons meteen een antwoord te bieden op wat we vragen. Een kritische houding blijft echter noodzakelijk; er zijn tal van voorbeelden hoe het met een AI-tunnelvisie kan mislopen. (Denk maar aan discriminatie, of aan hoe het gebruik van AI companions fatale gevolgen kan hebben.)
Het is een lange introductie voor iets wat me als onderzoeker tegenwoordig erg bezighoudt. Ik – en met mij het hele expertisecentrum PXL Smart ICT – wil samen met jullie landen in een wegwijzer rond AI-assistenten waarin iedereen weerbaar en veerkrachtig leert zijn als het gaat om duurzame en verantwoorde innovatie met AI. Een wegwijzer waarin een verhoging van de AI-geletterdheid inherent is aan de methodiek die moet worden toegepast. En waarin risico’s en onzekerheden door jullie zélf ontdekt kunnen worden. Wat dus wil zeggen dat iedereen zelf in staat is om nieuwe bewegingen in het AI-veld kritisch te evalueren naargelang zijn eigen noden.
Laat me beginnen met de risico’s en onzekerheden van de huidige modellen te schetsen. Ik zeg duidelijk: de huidige. Want de sector beweegt razendsnel, en volgende week ziet het er misschien weer anders uit…
Kunnen commerciële AI-diensten wel effectief onze verwachtingen inlossen?
Op het AI-forum van 2024 werd door Radix.ai (nu Superlinear) op een zeer interessante manier gevisualiseerd hoe de kennis van een AI-model verschilt met de kennis van ons als mens. Je kan de huidige status van het kennisgegeven visualiseren via twee ‘T-figuren’.
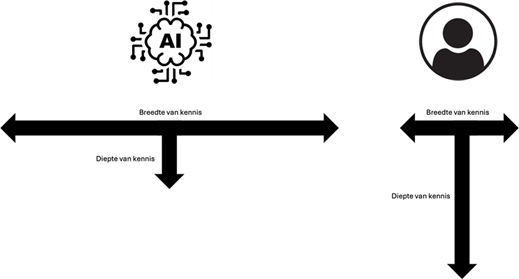
AI heeft de eigenschap dat het een veel bredere kennis heeft dan een persoon. Maar wat ons op dit moment nog steeds onderscheidt, is de diepte van onze kennis als persoon. Die is meer specifiek gericht op bepaalde takken (expertises van de persoon) en gaat dieper dan de expertise van de modellen waar we nu toegang toe hebben.
AI is dan ook getraind op gigantisch veel (online) beschikbare data. Wikipedia-artikels, sociale media, Reddit, noem maar op: het zit er allemaal in en dat zorgt ervoor dat AI taalkundig wel raad weet als het je moet verder helpen. Maar AI mist de ervaringen die wij als mens meenemen. Ervaringen die zich vaak schuilhouden in ons buikgevoel, en die niet noodzakelijk werden omgezet in digitale data de voorbije jaren.
ChatGPT is goed in doen alsof.
Inherent aan de architecturen waarmee de grote AI-modellen gebouwd worden is het verschijnsel van hallucinaties, waarbij AI-modellen feiten lijken te verzinnen. Zelfs de grote spelers geraken niet verder dan hooguit enkele lapmiddelen om die hallucinaties te voorkomen. Het AI-algoritme zal zocj vanwege zijn architectuur, waarin het statistische gemiddelden nastreeft, altijd een weg banen doorheen de feiten waar het op getraind is. Of zoals Steven Latré van imec het zo beeldend stelde in VRT NWS: “ChatGPT is bijzonder goed in het lijken alsof het intelligent is, maar eigenlijk is het niet meer dan een extreme vorm van patroonherkenning”.
Het antwoord dat ChatGPT formuleert op jouw vraag is niets meer dan een statistisch gemiddeld antwoord dat het kan vormen op basis van de brede zee van kennis die het leerde in zijn initiële trainingsfase. In de meeste gevallen is dit wel een antwoord dat jou kan verder helpen – opnieuw, ChatGPT is goed in doen alsof. Maar als je je vraag té breed definieert en niet stap-voor-stap aanpakt met het AI-model, dan geef je aan je AI-model de opdracht om net een bredere poel aan kennis te gebruiken om een antwoord te formuleren.
Statistici zullen het daarmee eens zijn: hoe groter het zoekgebied, hoe groter het risico op variatie (foutenmarges) aan de antwoordzijde. Om daarvoor een oplossing te bieden kwam men met ‘deep research’-varianten op de proppen. Die lijken wel een zekere verbetering op te leveren, maar volgen uiteindelijk toch maar een aanpak die stapsgewijs het zoekgebied van je vraag verkleint. Dat lost op zich wel een probleem van jou op, nl. het probleem waarin je je vraag niet specifiek genoeg stelt voor een AI-assistent zodat het jou ook geen passend antwoord kan bieden. Maar ‘deep research’-varianten blijven een lapmiddel, want ze veranderen niets aan de architectuur die hallucinaties veroorzaakt. Bovendien zijn ze een risico voor de gebruiker die een AI-model laat beslissen hoe een vraag moet worden opgedeeld in deelvragen. Want net in die opdeling van je vraag naar deelvragen schuilt erg veel van jouw domeinexpertise. Een diepgang van expertise die alleen wij hebben, en waar AI-modellen de dag van vandaag nog niet over beschikken.
Een AI-assistent afgestemd op de Europese waarden
Daarnaast hebben we het probleem van dataset bias. Een probleem dat op de proppen komt zodra wij als samenleving het hebben over normen en waarden. Een AI-model leert uiteindelijk taal en principes uit data zoals ze in de data beschreven staan. Zijn er meer Amerikaanse of Chinese data beschikbaar dan Europese data, dan zal het wellicht vaker gedrag vertonen dat dichter aanleunt bij de waarden van die culturen.
Dat is iets zeer fundamenteels waarvoor zelfs AI-bedrijven zelf niet meteen een kant-en-klare oplossing hebben. Een AI-bedrijf heeft zelf een intrinsieke bias naargelang de visie, waarden en normen die het zelf heeft. Dat kunnen allemaal zaken zijn die niet noodzakelijk overeenstemmen met de visie, waarden en normen van de samenleving waar het bedrijf deel van uitmaakt. Het verschilt tussen culturen onderling, maar zelfs binnen culturen is polarisatie een fenomeen.
Een perfecte ethische definitie voor wat ‘juist’ is, bestaat daardoor niet, waardoor ook een AI-model nooit zomaar ‘juist’ kan werken. Om het duidelijker en vatbaarder te maken, schets ik het probleem met een aantal voorbeelden.
Elon Musk introduceerde Grok-3, een AI-model dat de concurrentie zou moeten aangaan met de GPT-modellen van OpenAI, met Gemini en andere concurrenten. Wat bleek nu? Door slimme prompting kon je het model laten hallucineren en het guardrail barrières laten verbreken. Op die manier kon achterhaald worden wat er in de system prompt van dat model schuilging, d.w.z. in de basisinstructies die het gedrag van het model definiëren, de prompt die leveranciers van het model zelf instellen wanneer ze het ter beschikking stellen. Daarin was een verheerlijking van de heren Musk en Trump terug te vinden. Een verheerlijking die conflicteerde met de data waar het Grok-3 model op getraind werd, en waarin Elon Musk al iets kritischer bekeken werd, waardoor het model instabiel gedrag kan vertonen.
Opensource AI-modellen laten Europese ontwikkelaars toe bestaande architecturen over te nemen en naar hun eigen hand zetten.
Daarnaast is er ook het voorbeeld van het commerciële DeepSeek-model, dat op het eerste gezicht goed lijkt te werken, maar vanaf het moment dat een vraag een gevoelig Chinees onderwerp aanraakt, blijkt er een sterke vorm van bias naar boven te komen. Wat gebeurde er op het Tiananmenplein? Hoe zit het met Taiwan? Het model heeft er zijn eigen ideeën over en oordeelt dat het buiten zijn scope valt om erop te antwoorden.
Op het eerste gezicht lijken dit nogal specifieke voorbeelden te zijn die de AI-innovaties in ons landschap weinig zouden mogen beïnvloeden. Maar niets is minder waar, aangezien het fundamentele waarden, normen en visies aanraakt die kunnen verschillen. Wanneer er in onze regio wordt nagedacht over de inzet van AI die zich moet buigen over onze waarden en normen, komen er zeer grote risico’s en onzekerheden kijken bij het selecteren van een specifiek AI-model.
Visies en waarden met betrekking tot onderwijs, recht, gezondheid, inclusie, duurzaamheid enz.: overal waar wij in verschillen zou dit een element moeten zijn bij de overwegingen in de keuze van een AI-model, zodat het verantwoord kan worden ingezet. Liefst gekoppeld aan een uitgebreid testscenario, om zoveel mogelijk risico’s en onzekerheden in kaart te brengen.
Wel, laat ons dan een eigen model trainen dat wél over de juiste waarden beschikt, hoor ik u al denken. Welja, finetuning – een techniek voor het ‘specialiseren’ van AI-kennis naar een bepaald kennisdomein – kan soms helpen om specifieke problemen op te lossen. Maar zelfs voor finetuning is er infrastructuur nodig, en vaak een datahoeveelheid waar kmo’s niet zomaar eventjes over beschikken. Aangezien we hier in Europa veel voorzichtiger met onze privacygevoelige data omgaan, is het logisch dat Europa tragere stappen zet dan China of de VS.
Wel ontstaan er door het opensourcekarakter van DeepSeek enorme opportuniteiten voor Europa om een inhaalbeweging te maken, zoals ik al eerder stelde in een ander opiniestuk. Opensource AI-modellen laten Europese ontwikkelaars toe bestaande architecturen over te nemen en naar hun eigen hand zetten. Op die manier worden er al heel wat uitdagingen weggenomen: je kan immers vertrekken van een architectuur die al heeft aangetoond goed te werken.
Niet alleen de architectuur werd door DeepSeek vrijgegeven. Voor het eerst werden de centrale principes achter de chain-of-thought reasoning publiek gedeeld, wat Europa evenzeer helpt om een versnelling in gang te zetten. Wil je je model trainen op Europese waarden en normen, blijft wel de vraag hoe je voldoende kwalitatieve data kan verzamelen. Een grootschalige dataverzamelingsaanpak is dus vereist, zoals elke grote AI-speler dat al eerder moest doen.
Duurzame inzet van AI-modellen
We gingen al in op de hallucinaties van AI-modellen en hun risico’s, en de dataset bias die voor uitdagingen zorgt om de juiste waarden en normen te hanteren. Daarbij komt dan nog eens de razendsnelle evolutie van AI-modellen. Elke keer als je een keuze maakt, is die één maand later misschien al achterhaald. Hoe wapen je je daartegen?
In se is dit een probleem waar iedereen mee te maken heeft. Ook wij binnen ons praktijkwetenschappelijk onderzoek. In onze strategie staat verantwoorde en duurzame AI-adoptie alvast voorop. We zetten AI in en zijn continu op zoek naar hoe we onze partners veerkrachtig kunnen laten zijn bij de implementatie van AI.
Duurzame inzet van AI raakt twee belangrijke concepten aan: flexibiliteit en multidisciplinariteit.
- Flexibiliteit draait om veerkracht. Veerkracht die zich buigt over de AI-tools die je inzet, en veerkracht die terugkomt in de AI-geletterdheid, zodat je nieuwe bewegingen snel naar je hand kan zetten. Zorg ervoor dat je tools omarmt die vlot kunnen meebewegen met nieuwe ontwikkelingen. Zo kun je een AI-leverancier kiezen die je vertrouwt omdat hij zelf meeblijft met de ‘state-of-the-art’, of een middenspeler die tools zoveel mogelijk centraliseert.
- Nieuwe bewegingen in AI snel naar je hand zetten kan enkel en alleen via multidisciplinaire samenwerking. Krachten moeten gebundeld worden om problemen uit het domein te identificeren waarvoor AI een oplossing kan bieden. Enerzijds heeft de technische kant de gebruikerskant en haar domeinkennis nodig om na te gaan hoe de probleemstellingen zich als patronen schuilhouden in de data. Anderzijds heeft de gebruikerskant de technische kant nodig om mee te blijven met alle risico’s en onzekerheden die continu evolueren. Het is een vorm van multidisciplinariteit die perfect één op één terugkomt in het boek ‘Mens vs. Machine’. Daarin stelt Mieke de Ketelaere dat er AI-vertalers nodig zijn tussen verschillende disciplines om duurzame AI-innovatie mogelijk te maken. Ik sprak hier al over gebruikers en technici, maar het strekt zich verder uit tot alle stakeholders in een innovatietraject. Dus ook managers en betrokken juridische en ethische experts.
In het AI-onderzoek van PXL Smart ICT definiëren we voor flexibiliteit een modulair framework ‘Pixie’. Pixie is in staat om mee te evolueren met nieuwe modellen en laat zich vlot integreren in een brede waaier van diverse systemen en processen. Pixie is dus een toolbox waarin via een heel implementatiekader de juiste componenten geselecteerd kunnen worden, zodat je vraag correct beantwoord kan worden.
Noem het een wegwijzer voor zowel de vragende partij als de AI-aanbieder, waarin samen naar de correcte aanpak wordt gezocht. Een probleem wordt opgelost door behalve alle implementatievereisten (bv. cloud vs lokaal, taalondersteuning) ook substantiële elementen zoals dataset bias, hallucinaties en zelfs ecologische voetafdrukken mee te nemen. Een wegwijzer dus die vertrekt vanuit een vast implementatiestramien, maar een nieuwe vorm kan krijgen in alle domeinen waar Pixie potentieel relevant is.
AI implementeren doet niemand alleen
Als AI-onderzoeker zou ik graag alle problemen van de wereld willen oplossen. Het lijkt zo simpel om dat te doen met een technologie die alles fantastisch makkelijk doet lijken, maar na negen jaar in het vakgebied besef ik hoe dit enkel mogelijk is als we samen met domeinexperten het probleem definiëren.
Samen moeten we zoeken hoe AI een oplossing kan zijn voor een probleem, zodat we ons samen veerkrachtig kunnen opstellen te midden van alle uitdagingen die de snelle evoluties op ons afvuren. Samen moet er gezocht worden naar de juiste methodieken en de juiste doelstellingen om verantwoord en duurzaam gebruik te garanderen.
De boodschap is om zelf te evolueren zoals AI evolueert. Tot één grote community.
In ons PXL Smart ICT-onderzoek zijn we nu druk in de weer om dat kader vanuit technisch perspectief te schetsen. Maar enkel door samenwerking kan een wegwijzer doorheen de uitdagingen, onzekerheden en risico’s van AI-assistenten verder vorm krijgen en resulteren in een duurzaam concept dat multi-inzetbaar is. Alleen zo creëren we – via datzelfde concept – veerkracht. Veerkracht bij bedrijven en onderzoekers in een snel veranderende wereld.
De boodschap is om zelf te evolueren zoals AI evolueert. Binnen AI zat kennis altijd vertakt in algoritmes rond beeldverwerkingstechnieken, voorspellende analyses op tijdsdata of bijvoorbeeld tabulaire data. Kortom: AI zat lang verscholen in silo’s, in verschillende domeinen, net zoals onze expertise en onze domeinkennis vaak nog verspreid zit in silo’s.
Maar AI? Alle kennis in AI werd samengevoegd in taal. Taal die al die domeinen leerde samennemen in één en dezelfde communicatievorm. Laten we dat voorbeeld volgen en zelf ook samensmelten tot één grote AI-community die van elkaar kan leren. Want als onze doelstelling écht is om duurzame AI-innovatie na te streven, hebben we geen andere keuze…
Contact: robin.schrijvers@pxl.be